











 William Charles
William Charles 0
0  1754
1754 302
302
Artikel opdateret af Joel Lee den 10/10/2017
For mange, Google er internettet. Det er udgangspunktet for at finde nye websteder, og det er uden tvivl den vigtigste opfindelse siden selve internettet. Uden søgemaskiner ville nyt webindhold være utilgængeligt for masserne.
Men ved du, hvordan søgemaskiner fungerer? Hver søgemaskine har tre hovedfunktioner: gennemsøgning (for at finde indhold), indeksering (for at spore og gemme indhold) og hentning (for at hente relevant indhold, når brugerne spørger efter søgemaskinen).
Gennemgang
Gennemgang er hvor det hele begynder: erhvervelse af data om et websted.
Dette involverer scanning af websteder og indsamling af detaljer om hver side: titler, billeder, nøgleord, andre sammenkædede sider osv. Forskellige crawlers kan også se efter forskellige detaljer, f.eks. Sidelayouts, hvor annoncer er placeret, om links er proppet ind osv..
Men hvordan gennemgås et websted? En automatiseret bot (kaldet a “edderkop”) besøger side efter side så hurtigt som muligt ved hjælp af sidekoblinger til at finde, hvor man skal gå næste gang. Selv i de tidligste dage kunne Googles edderkopper læse flere hundrede sider i sekundet. I dag er det i tusinder.
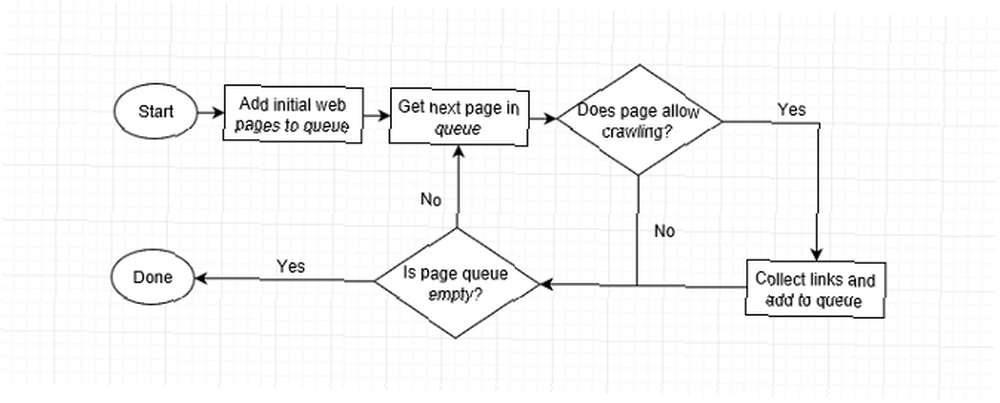
Når en webcrawler besøger en side, indsamler den hvert link på siden og føjer dem til listen over de næste sider, der skal besøges. Den går til næste side på listen, samler linkene på at side og gentages. Webcrawlere gentager også tidligere sider en gang imellem for at se, om der er sket ændringer.
Dette betyder, at ethvert websted, der er linket fra et indekseret sted, til sidst gennemgås. Nogle steder gennemgås hyppigere, og nogle gennemgås til større dybder, men nogle gange kan en crawler give op, hvis et websteds sidehierarki er for kompliceret.
En måde at forstå, hvordan en webcrawler fungerer, er at opbygge en selv. Vi har skrevet en tutorial om oprettelse af en grundlæggende webcrawler i PHP, så tjek det ud, hvis du har nogen programmeringserfaring.

Bemærk, at sider kan markeres som “noindex,” hvilket er som at bede søgemaskiner om at springe dens indeksering over. Ikke-indekserede dele af internettet er kendt som “dyb web” Hvad er det dybe web? Det er mere vigtigt end du tænker, hvad er Deep Web? Det er mere vigtigt end du tror. Den dybe web og den mørke web lyder både skræmmende og uærlige, men farerne er blevet overdrevne. Her er hvad de faktisk har, og hvordan du selv kan få adgang til dem selv! , og nogle websteder, som dem, der hostes på TOR-netværket, kan ikke indekseres af søgemaskiner. (Hvad er TOR og løg routing? Hvad er løg routing, nøjagtigt? [MakeUseOf forklarer] Hvad er løg routing, nøjagtigt? [MakeUseOf forklarer] Internet-privatliv. Anonymitet var en af de største funktioner på Internettet i sin ungdom (eller en af dets værste træk, afhængigt af hvem du spørger.) Ved at lægge de slags problemer, der springer frem ...)
Indeksering
Indeksering sker, når dataene fra en gennemgang behandles og placeres i en database.
Forestil dig at lave en liste over alle de bøger, du ejer, deres udgivere, deres forfattere, deres genrer, deres sidetællinger osv. Gennemsøgning er, når du kæmmer gennem hver bog, mens indeksering er, når du logger dem på din liste.
Forestil dig nu, at det ikke kun er et rum fyldt med bøger, men alle biblioteker i verden. Det er en lille version af, hvad Google gør, som gemmer alle disse data i store datacentre med tusinder af drev af petabytes værd. Hukommelsesstørrelser forklaret: Gigabyte, Terabyte og Petabyte i konteksthukommelsesstørrelser forklaret: Gigabyte, Terabyte og Petabyte i sammenhæng Det er let at se, at 500 GB er mere end 100 GB. Men hvordan sammenlignes forskellige størrelser? Hvad er en gigabyte til en terabyte? Hvor passer en petabyte ind? Lad os rydde op! .
Her er et kig i et af Googles søgedatacentre:
 Billedkredit: Google
Billedkredit: Google
Hentning og placering
Hentning er, når søgemaskinen behandler din søgning og returnerer de mest relevante sider, der matcher din forespørgsel.
De fleste søgemaskiner differentierer sig ved hjælp af deres hentningsmetoder: de bruger forskellige kriterier til at vælge og vælge hvilke sider der passer bedst til det, du vil finde. Derfor varierer søgeresultaterne mellem Google og Bing, og hvorfor Wolfram Alpha er så unikt nyttigt 10 seje anvendelser af Wolfram Alpha, hvis du læser og skriver på det engelske sprog 10 Cool anvendelse af Wolfram Alpha, hvis du læser og skriver på det engelske sprog, det tog mig lidt tid til at vikle mit hoved omkring Wolfram Alpha og de spørgsmål, det bruger til at tappe ud disse resultater. Du er nødt til at dykke dybt ned i Wolfram Alpha for virkelig at udnytte det til ... .
Rangeringsalgoritmer kontrollerer din søgning mod milliarder sider for at bestemme hver enkeltes relevans. Virksomheder beskytter deres rangeringsalgoritmer som patenterede industrihemmeligheder på grund af deres kompleksitet. En bedre algoritme oversættes til en bedre søgeoplevelse.
De ønsker heller ikke, at webskabere skal spille systemet og uretfærdigt klatre til toppen af søgeresultaterne. Hvis den interne metode til en søgemaskine nogensinde kom ud, ville alle slags mennesker helt sikkert udnytte denne viden til skade for søgere som dig og mig.
 Billedkredit: fotovibber via Shutterstock
Billedkredit: fotovibber via Shutterstock
Udnyttelse af søgemaskiner er muligvis, selvfølgelig, men er ikke så let længere.
Oprindeligt rangerede søgemaskinerne efter, hvor ofte nøgleord blev vist på en side, hvilket førte til “søgeord fyldning” - at fylde sider med nøgleord-tung vrøvl.
Så kom konceptet om linkvigtighed: søgemaskiner værdsatte websteder med masser af indgående links, fordi de fortolkede websteds popularitet som relevans. Men dette førte til linkspamming over hele internettet. I dag vægtlink søgemaskiner afhængigt af “myndighed” af det linkende sted. Søgemaskiner lægger mere værdi på links fra et regeringsorgan end links fra et link-bibliotek.
I dag er rangeringsalgoritmer indhyllet i mere mysterium end nogensinde før, og “Søgemaskine optimering” Demystify SEO: 5 Guider til søgemaskineoptimering, der hjælper dig med at begynde Demystify SEO: 5 Guider til søgemaskineoptimering, der hjælper dig med at starte Søgemaskins mestring tager viden, erfaring og masser af prøve og fejl. Du kan begynde at lære de grundlæggende og undgå almindelige SEO-fejl nemt ved hjælp af mange SEO-guider, der er tilgængelige på Internettet. er ikke så vigtig. Gode placeringer i søgemaskinerne kommer nu fra indhold af høj kvalitet og gode brugeroplevelser.
Hvad er det næste efter søgemaskiner?
Ah, nu er der et interessant spørgsmål. Svaret er “semantik”: det betyder af sidens indhold. Du kan omkring i vores oversigt over semantisk markup og dens fremtidige virkning Hvad semantisk markup er & hvordan det vil ændre internettet for evigt [Teknologi forklaret] Hvad semantisk markup er & hvordan det vil ændre Internettet for evigt [Teknologi forklaret] .
Men her er vigtigheden af det.
Lige nu kan du søge efter “glutenfrie cookies” men resultaterne returnerer muligvis opskrifter på glutenfri cookies. I stedet for kan du finde regelmæssige cookie-opskrifter, der siger “Denne opskrift er ikke glutenfri.” Det har de rigtige nøgleord, men den forkerte betydning.
Med semantik kan du søge efter cookie-opskrifter og derefter fjerne bestemte ingredienser: mel, nødder osv. Du kan også indsnævre resultater til kun opskrifter med forberedelsestider på mindre end 30 minutter og gennemgå scoringer på 4/5 eller mere. At ville være cool, ikke? Det er der vi er på vej hen!
Stadig forvirret over, hvordan søgemaskiner fungerer? Se, hvordan Google forklarer processen:
Hvis du fandt dette interessant, kan du måske også lide at lære om, hvordan billede søgemaskiner fungerer.
Billedkredit: prykhodov / Depositphotos